前言
最近在公司一直在做java爬虫,选用的是webmagic,问为什么就是这个爬虫框架真是简单好用。首先贴一下webmagic的官网地址:http://webmagic.io/
这篇文章主要是讲一下使用webMagic的监听模块完成爬虫可视化界面的编写、如何使用代理ip爬取页面以及对框架进行一些小改动实现增量爬取。不涉及webMagic的基础使用,这些可以看作者的文档,介绍的很详细了,上手很快~
tip:现在maven中央仓库可以使用0.7.4的版本了,具体的改动我没有看,但是我需要的SpiderListener的onError方法可以传Exception了,这点真心超赞的,可以实现爬取页面出错时的错误记录了。
一、引入WebMagic依赖
maven项目的话使用webMagic是很简单的,在pom.xml中加入依赖即可,使用jar包的话请自行下载jar包然后addlibrary或build
如果Scheduler使用的过滤器并不是布隆过滤,那么第三个可以考虑不用加
<!-- https://mvnrepository.com/artifact/us.codecraft/webmagic-core -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/us.codecraft/webmagic-extension -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.4</version>
</dependency>
<!--WebMagic对布隆过滤器的支持-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0</version>
</dependency>
二、冲!
1.使用SpiderMonitor监控爬虫运行状态
spiderMonitor简单来说就是运行时可以动态获取那些注册进来的爬虫的运行状态,分析源码可以知道他是通过一个List来保存所有注册进来的爬虫。这个类下面还有一个内部类SpiderListener,他的功能主要是监听爬虫的执行过程中的成功和失败状态,然后做出响应,其中记录的有成功/失败任务数量,失败的url等信息。但是有一个问题是通过List来保存爬虫状态会导致从外部来取某一个爬虫的时候都需要遍历这个list,所以可以修改成Map来保存,这样在外面直接get就可以啦~上代码
import com.ahdx.spider.Spider;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.SpiderListener;
import us.codecraft.webmagic.monitor.SpiderStatusMXBean;
import javax.management.*;
import java.io.Serializable;
import java.lang.management.ManagementFactory;
import java.net.SocketTimeoutException;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicBoolean;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j
public class MySpiderMonitor {
private static MySpiderMonitor INSTANCE = new MySpiderMonitor();
private AtomicBoolean started = new AtomicBoolean(false);
private MBeanServer mbeanServer;
private String jmxServerName;
private ConcurrentHashMap<String, MySpiderStatus> spiderStatuses = new ConcurrentHashMap<>();
protected MySpiderMonitor() {
jmxServerName = "WebMagic";
mbeanServer = ManagementFactory.getPlatformMBeanServer();
}
public Map<String, MySpiderStatus> getSpiderStatuses() {
return spiderStatuses;
}
/**
* Register spider for monitor.
*
* @param spiders spiders
* @return this
*/
public synchronized MySpiderMonitor register(Spider... spiders) throws JMException {
for (Spider spider : spiders) {
MyMonitorSpiderListener monitorSpiderListener = new MyMonitorSpiderListener();
if (spider.getSpiderListeners() == null) {
List<SpiderListener> spiderListeners = new ArrayList<SpiderListener>();
spiderListeners.add(monitorSpiderListener);
spider.setSpiderListeners(spiderListeners);
} else {
spider.getSpiderListeners().add(monitorSpiderListener);
}
MySpiderStatus spiderStatusMBean = getSpiderStatusMBean(spider, monitorSpiderListener);
registerMBean(spiderStatusMBean);
spiderStatuses.put(spider.getUUID(), spiderStatusMBean);
}
return this;
}
protected MySpiderStatus getSpiderStatusMBean(Spider spider, MyMonitorSpiderListener monitorSpiderListener) {
return new MySpiderStatus(spider, monitorSpiderListener);
}
protected void registerMBean(SpiderStatusMXBean spiderStatus) throws MalformedObjectNameException, InstanceAlreadyExistsException, MBeanRegistrationException, NotCompliantMBeanException {
ObjectName objName = new ObjectName(jmxServerName + ":name=" + spiderStatus.getName());
if (!mbeanServer.isRegistered(objName)) {
mbeanServer.registerMBean(spiderStatus, objName);
}
}
public static MySpiderMonitor instance() {
return INSTANCE;
}
public class MyMonitorSpiderListener implements SpiderListener {
private final AtomicInteger successCount = new AtomicInteger(0);
private final AtomicInteger errorCount = new AtomicInteger(0);
private List<String> errorUrls = Collections.synchronizedList(new ArrayList<String>());
private List<ErrorDetail> errorPages = Collections.synchronizedList(new ArrayList<ErrorDetail>());
@Override
public void onSuccess(Request request) {
successCount.incrementAndGet();
}
@Override
public void onError(Request request) {
errorUrls.add(request.getUrl());
errorCount.incrementAndGet();
}
@Override
public void onError(Request request, Exception e) {
onError(request);
errorPages.add(new ErrorDetail(request.getUrl(), getErrorReason(e)));
}
private String getErrorReason(Exception e) {
String reason = e.getLocalizedMessage();
if (e instanceof SocketTimeoutException) {
reason = "代理ip连接超时";
}
return reason;
}
public AtomicInteger getSuccessCount() {
return successCount;
}
public AtomicInteger getErrorCount() {
return errorCount;
}
public List<String> getErrorUrls() {
return errorUrls;
}
public List<ErrorDetail> getErrorPages() {
return errorPages;
}
}
public class ErrorDetail implements Serializable {
public String url;
public String reason;
public ErrorDetail() {}
public ErrorDetail(String url, String reason) {
this.url = url;
this.reason = reason;
}
}
}
import com.ahdx.spider.Spider;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.monitor.SpiderStatusMXBean;
import us.codecraft.webmagic.scheduler.MonitorableScheduler;
import java.util.Date;
import java.util.List;
@Slf4j
public class MySpiderStatus implements SpiderStatusMXBean {
protected final Spider spider;
protected final MySpiderMonitor.MyMonitorSpiderListener monitorSpiderListener;
public MySpiderStatus(Spider spider, MySpiderMonitor.MyMonitorSpiderListener monitorSpiderListener) {
this.spider = spider;
this.monitorSpiderListener = monitorSpiderListener;
}
public Spider getSpider()
{
return this.spider;
}
public String getName() {
return spider.getUUID();
}
public int getLeftPageCount() {
if (spider.getScheduler() instanceof MonitorableScheduler) {
return ((MonitorableScheduler) spider.getScheduler()).getLeftRequestsCount(spider);
}
log.warn("Get leftPageCount fail, try to use a Scheduler implement MonitorableScheduler for monitor count!");
return -1;
}
public int getTotalPageCount() {
if (spider.getScheduler() instanceof MonitorableScheduler) {
return ((MonitorableScheduler) spider.getScheduler()).getTotalRequestsCount(spider);
}
log.warn("Get totalPageCount fail, try to use a Scheduler implement MonitorableScheduler for monitor count!");
return -1;
}
@Override
public int getSuccessPageCount() {
return monitorSpiderListener.getSuccessCount().get();
}
@Override
public int getErrorPageCount() {
return monitorSpiderListener.getErrorCount().get();
}
public List<String> getErrorPages() {
return monitorSpiderListener.getErrorUrls();
}
@Override
public String getStatus() {
return spider.getStatus().name();
}
@Override
public int getThread() {
return spider.getThreadNum();
}
public String getSpiderType() {
return spider.getSpiderType();
}
public void start() {
spider.start();
}
public void stop() {
spider.stop();
}
@Override
public Date getStartTime() {
return spider.getStartTime();
}
@Override
public int getPagePerSecond() {
int runSeconds;
if (spider.getEndTime() == null) {
runSeconds = (int) (System.currentTimeMillis() - getStartTime().getTime()) / 1000;
} else {
runSeconds = (int) (spider.getEndTime().getTime() - getStartTime().getTime()) / 1000;
}
if (runSeconds == 0)
return 0;
return getSuccessPageCount() / runSeconds;
}
public int getPagePerMin() {
int runMin;
if (spider.getEndTime() == null) {
runMin = (int) (System.currentTimeMillis() - getStartTime().getTime()) / (60 * 1000);
} else {
runMin = (int) (spider.getEndTime().getTime() - getStartTime().getTime()) / (60 * 1000);
}
if (runMin == 0)
return 0;
return getSuccessPageCount() / runMin;
}
public List<MySpiderMonitor.ErrorDetail> getErrorPagesDetail() {
return monitorSpiderListener.getErrorPages();
}
}
相比于SpiderMonitor,修改了其中的List为Map,然后增加了错误页面的url及失败原因详情。使用的时候和原版保持不变,获取单例对象,然后将创建的Spider注册进去就可以了
2.使用ProxyProvider进行代理的爬取
downloader下载页面之前会判断是否设置了proxyProvider,如果设置了那么会对应的调用getProxy方法,所以我们只需要实现ProxyProvider这个接口,重写一下getProxy这个方法就可以啦
@Override
public Page download(Request request, Task task) {
if (task == null || task.getSite() == null) {
throw new NullPointerException("task or site can not be null");
}
CloseableHttpResponse httpResponse = null;
CloseableHttpClient httpClient = getHttpClient(task.getSite());
Proxy proxy = proxyProvider != null ? proxyProvider.getProxy(task) : null; HttpClientRequestContext requestContext = httpUriRequestConverter.convert(request, task.getSite(), proxy);
Page page = Page.fail();
try {
httpResponse = httpClient.execute(requestContext.getHttpUriRequest(), requestContext.getHttpClientContext());
page = handleResponse(request, request.getCharset() != null ? request.getCharset() : task.getSite().getCharset(), httpResponse, task);
onSuccess(request);
logger.info("downloading page success {}", request.getUrl());
return page;
} catch (IOException e) {
logger.warn("download page {} error", request.getUrl(), e);
onError(request);
return page;
} finally {
if (httpResponse != null) {
//ensure the connection is released back to pool
EntityUtils.consumeQuietly(httpResponse.getEntity());
}
if (proxyProvider != null && proxy != null) {
proxyProvider.returnProxy(proxy, page, task);
}
}
}
?上面红色部分可以看到会判断设置的ProxyProvider是否为null,不为null则调用getProxy方法
看一下伪代码
import cn.hutool.core.convert.Convert;
import com.ahdx.common.Constant;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.proxy.Proxy;
import us.codecraft.webmagic.proxy.ProxyProvider;
/**
* @author yany
* @desc 自定义的请求代理类
*/
@Slf4j
@Component
public class MyProxyProvider implements ProxyProvider {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Autowired
private AgentIpPool ipPool;
@Override
public void returnProxy(Proxy proxy, Page page, Task task) {
if (!page.isDownloadSuccess()) {
// 说明没有下载成功,则通知redis进行这个代理ip的销毁
redisTemplate.opsForList().remove(Constant.REDIS_PROXY_IP_NAME, 0, proxy.getHost() + ":" + proxy.getPort());
}
}
@Override
public Proxy getProxy(Task task) {
String host = "";
int port = 0;
return new Proxy(host, port);
}
}
对于代理ip最好是维护一个ip池,我自己用的是使用redis来维护这个ip池,定时检测无效的ip进行删除,另外作者提供了一个returnProxy方法,在这个方法里面一样可以检测页面是否是下载失败的,也可以进行无效ip的删除。使用的时候把自己的ProxyProvider设置到downloader中去就可以了
// downloader调用这个方法设置proxyProvider ↓
httpClientDownloader.setProxyProvider(proxyProvider);
3.增量爬取
本身框架的设计中是不支持增量爬取的,所以我们需要找其他的办法来实现,首先先看一下爬虫大概的执行流程
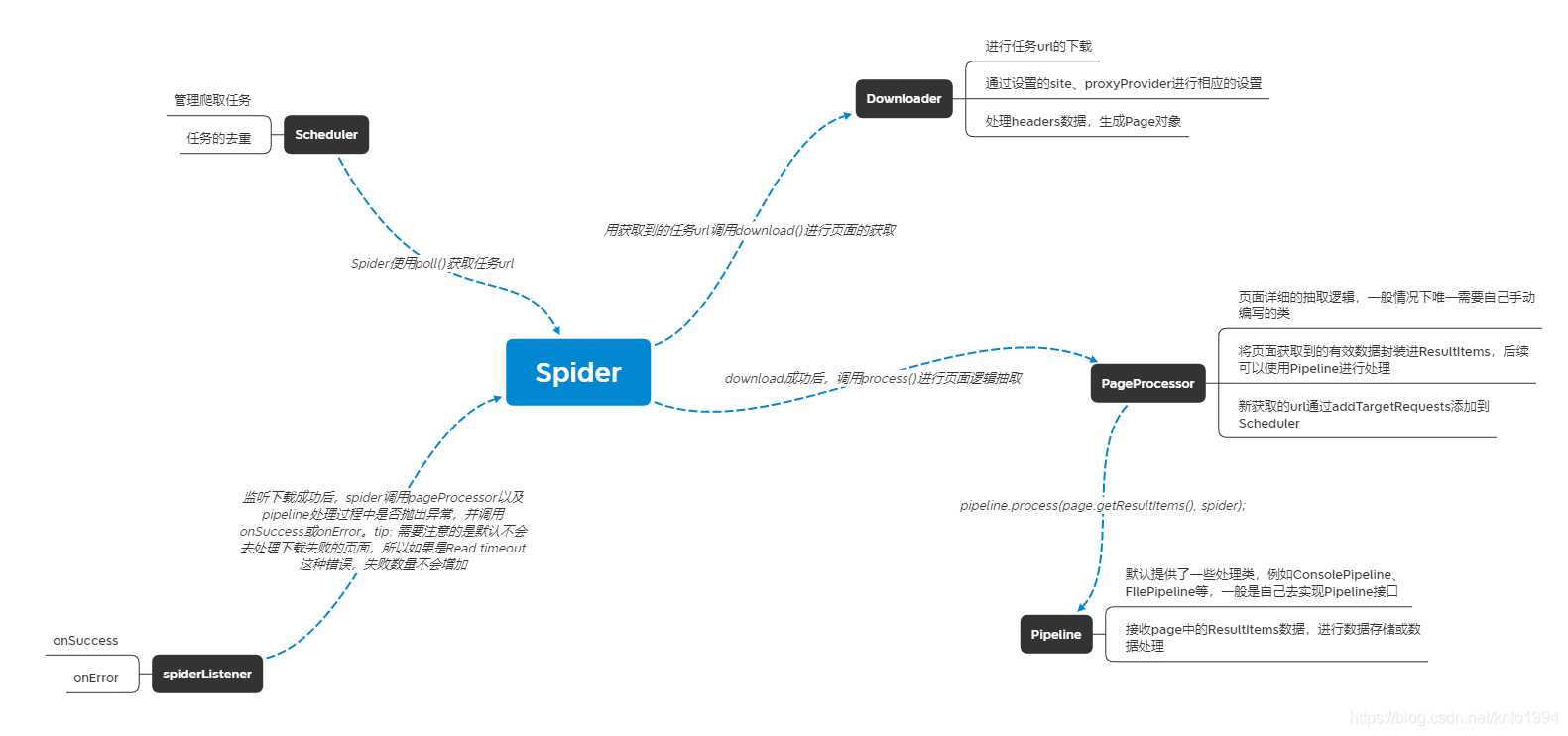
所以我想着如果要实现增量爬取,那其实就是针对PageProcessor,只有页面解析到时间超过了设置的时间阈值,那么就需要通知Spider进行stop()。所以如果是列表页获取到时间,那么可以判断时间条件,如果超过阈值就不再将详情页的url加入到任务队列中,如果是详情页,那么就通知Spider调用stop()。最后一点,如果是分布式爬虫,上面的方法依然是适用的,但如果只想使用一个爬虫来控制增量爬取,其他的爬虫只负责从队列中取任务进行解析的话,就可以从Scheduler入手,如果检测到到达增量爬取的阈值,那么就可以将任务队列中的url清空,这样所有的爬虫任务就都会停止了。来,看下代码片段 ↓
pageProcessor中判断爬取阈值,根据自己的业务需要,找到需要跳出的位置。除非修改框架源码,否则在PageProcessor能获取到的对象很少,本身我也是想在SIte中设置跳出的headers,但是不太可行,getSite方法每次获取到的都是new Site()对象,没办法,只能使用了Page对象。
List<AccountBaseInfo> checkList = baseInfoList.stream().filter(bi -> {
try {
DateTime parse = DateUtil.parse(bi.getSellingTime());
return (new Date().getTime() - parse.getTime()) >= 2 * 60 * 60 * 1000;
} catch (Exception e) {
return false;
}
}).collect(Collectors.toList());
if (checkList.size() > 0) {
// 说明已经存在超过增量爬取上限的url了
page.getHeaders().put(Constant.INCREMENTAL_RUN, Collections.singletonList("yes"));
return;
}
实现增量爬取的话需要自己重写Spider的类,贴一下
import com.ahdx.common.Constant;
import com.ahdx.processor.BasePageProcessor;
import com.ahdx.scheduler.MyRedisPriorityScheduler;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.SerializationUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import us.codecraft.webmagic.*;
import us.codecraft.webmagic.downloader.Downloader;
import us.codecraft.webmagic.downloader.HttpClientDownloader;
import us.codecraft.webmagic.pipeline.CollectorPipeline;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.pipeline.ResultItemsCollectorPipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.scheduler.QueueScheduler;
import us.codecraft.webmagic.scheduler.Scheduler;
import us.codecraft.webmagic.thread.CountableThreadPool;
import us.codecraft.webmagic.utils.UrlUtils;
import us.codecraft.webmagic.utils.WMCollections;
import java.io.Closeable;
import java.io.IOException;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class Spider implements Runnable, Task {
protected Downloader downloader;
protected List<Pipeline> pipelines = new ArrayList<Pipeline>();
protected PageProcessor pageProcessor;
protected List<Request> startRequests;
protected Site site;
protected String uuid;
protected Scheduler scheduler = new QueueScheduler();
protected Logger logger = LoggerFactory.getLogger(getClass());
protected CountableThreadPool threadPool;
protected ExecutorService executorService;
protected int threadNum = 1;
protected AtomicInteger stat = new AtomicInteger(STAT_INIT);
protected boolean exitWhenComplete = true;
protected final static int STAT_INIT = 0;
protected final static int STAT_RUNNING = 1;
protected final static int STAT_STOPPED = 2;
protected boolean spawnUrl = true;
protected boolean destroyWhenExit = true;
protected String spiderType;
private ReentrantLock newUrlLock = new ReentrantLock();
private Condition newUrlCondition = newUrlLock.newCondition();
private List<SpiderListener> spiderListeners;
private final AtomicLong pageCount = new AtomicLong(0);
private Date startTime;
private Date updateTime;
private Date endTime;
private int emptySleepTime = 30000;
// 动态切换Site
private ConcurrentHashMap<String, Site> dynamicSite;
// 是否需要增量爬取页面,需要Processor的支持才行
private boolean incrementalRun;
// 是否已经到达了增量爬取的设置上限
private boolean topLimit;
/**
* create a spider with pageProcessor.
*
* @param pageProcessor pageProcessor
* @return new spider
* @see PageProcessor
*/
public static Spider create(PageProcessor pageProcessor) {
return new Spider(pageProcessor);
}
/**
* create a spider with pageProcessor.
*
* @param pageProcessor pageProcessor
*/
public Spider(PageProcessor pageProcessor) {
this.pageProcessor = pageProcessor;
this.site = pageProcessor.getSite();
}
/**
* Set startUrls of Spider.<br>
* Prior to startUrls of Site.
*
* @param startUrls startUrls
* @return this
*/
public Spider startUrls(List<String> startUrls) {
checkIfRunning();
this.startRequests = UrlUtils.convertToRequests(startUrls);
return this;
}
/**
* Set startUrls of Spider.<br>
* Prior to startUrls of Site.
*
* @param startRequests startRequests
* @return this
*/
public Spider startRequest(List<Request> startRequests) {
checkIfRunning();
this.startRequests = startRequests;
return this;
}
/**
* Set an uuid for spider.<br>
* Default uuid is domain of site.<br>
*
* @param uuid uuid
* @return this
*/
public Spider setUUID(String uuid) {
this.uuid = uuid;
return this;
}
/**
* set scheduler for Spider
*
* @param scheduler scheduler
* @return this
* @see #setScheduler(us.codecraft.webmagic.scheduler.Scheduler)
*/
@Deprecated
public Spider scheduler(Scheduler scheduler) {
return setScheduler(scheduler);
}
/**
* set scheduler for Spider
*
* @param scheduler scheduler
* @return this
* @see Scheduler
* @since 0.2.1
*/
public Spider setScheduler(Scheduler scheduler) {
checkIfRunning();
Scheduler oldScheduler = this.scheduler;
this.scheduler = scheduler;
if (oldScheduler != null) {
Request request;
while ((request = oldScheduler.poll(this)) != null) {
this.scheduler.push(request, this);
}
}
return this;
}
/**
* add a pipeline for Spider
*
* @param pipeline pipeline
* @return this
* @see #addPipeline(us.codecraft.webmagic.pipeline.Pipeline)
* @deprecated
*/
@Deprecated
public Spider pipeline(Pipeline pipeline) {
return addPipeline(pipeline);
}
/**
* add a pipeline for Spider
*
* @param pipeline pipeline
* @return this
* @see Pipeline
* @since 0.2.1
*/
public Spider addPipeline(Pipeline pipeline) {
checkIfRunning();
this.pipelines.add(pipeline);
return this;
}
/**
* set pipelines for Spider
*
* @param pipelines pipelines
* @return this
* @see Pipeline
* @since 0.4.1
*/
public Spider setPipelines(List<Pipeline> pipelines) {
checkIfRunning();
this.pipelines = pipelines;
return this;
}
/**
* clear the pipelines set
*
* @return this
*/
public Spider clearPipeline() {
pipelines = new ArrayList<Pipeline>();
return this;
}
/**
* set the downloader of spider
*
* @param downloader downloader
* @return this
* @see #setDownloader(us.codecraft.webmagic.downloader.Downloader)
* @deprecated
*/
@Deprecated
public Spider downloader(Downloader downloader) {
return setDownloader(downloader);
}
/**
* set the downloader of spider
*
* @param downloader downloader
* @return this
* @see Downloader
*/
public Spider setDownloader(Downloader downloader) {
checkIfRunning();
this.downloader = downloader;
return this;
}
protected void initComponent() {
if (downloader == null) {
this.downloader = new HttpClientDownloader();
}
if (pipelines.isEmpty()) {
pipelines.add(new ConsolePipeline());
}
downloader.setThread(threadNum);
if (threadPool == null || threadPool.isShutdown()) {
if (executorService != null && !executorService.isShutdown()) {
threadPool = new CountableThreadPool(threadNum, executorService);
} else {
threadPool = new CountableThreadPool(threadNum);
}
}
if (startRequests != null) {
for (Request request : startRequests) {
addRequest(request);
}
startRequests.clear();
}
if (startTime == null) {
startTime = new Date();
} else {
updateTime = new Date();
}
if (topLimit) {
topLimit = false;
}
// 重新启动的时候,清除endTime
endTime = null;
}
@Override
public void run() {
checkRunningStat();
initComponent();
logger.info("Spider {} started!",getUUID());
while (!Thread.currentThread().isInterrupted() && stat.get() == STAT_RUNNING) {
final Request request = scheduler.poll(this);
if (request == null) {
if (threadPool.getThreadAlive() == 0 && exitWhenComplete) {
break;
}
// wait until new url added
waitNewUrl();
} else {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
processRequest(request);
onSuccess(request);
} catch (Exception e) {
onError(request, e);
logger.error("process request " + request + " error", e);
} finally {
pageCount.incrementAndGet();
signalNewUrl();
}
}
});
}
}
stat.set(STAT_STOPPED);
// release some resources
if (destroyWhenExit) {
close();
}
endTime = new Date();
logger.info("Spider {} closed! {} pages downloaded.", getUUID(), pageCount.get());
}
/**
* @deprecated Use {@link #onError(Request, Exception)} instead.
*/
@Deprecated
protected void onError(Request request) {
Scheduler scheduler = this.getScheduler();
if (scheduler instanceof MyRedisPriorityScheduler) {
MyRedisPriorityScheduler s = (MyRedisPriorityScheduler) scheduler;
s.deleteErrorUrl(request, this);
s.pushErrorUrl(request, this);
}
}
protected void onError(Request request, Exception e) {
this.onError(request);
if (CollectionUtils.isNotEmpty(spiderListeners)) {
for (SpiderListener spiderListener : spiderListeners) {
spiderListener.onError(request, e);
}
}
}
protected void onSuccess(Request request) {
if (CollectionUtils.isNotEmpty(spiderListeners)) {
for (SpiderListener spiderListener : spiderListeners) {
spiderListener.onSuccess(request);
}
}
}
private void checkRunningStat() {
while (true) {
int statNow = stat.get();
if (statNow == STAT_RUNNING) {
throw new IllegalStateException("Spider is already running!");
}
if (stat.compareAndSet(statNow, STAT_RUNNING)) {
break;
}
}
}
public void close() {
destroyEach(downloader);
destroyEach(pageProcessor);
destroyEach(scheduler);
for (Pipeline pipeline : pipelines) {
destroyEach(pipeline);
}
threadPool.shutdown();
}
private void destroyEach(Object object) {
if (object instanceof Closeable) {
try {
((Closeable) object).close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* Process specific urls without url discovering.
*
* @param urls urls to process
*/
public void test(String... urls) {
initComponent();
if (urls.length > 0) {
for (String url : urls) {
processRequest(new Request(url));
}
}
}
private void processRequest(Request request) {
Page page;
if (null != request.getDownloader()){
page = request.getDownloader().download(request,this);
}else {
page = downloader.download(request, this);
}
if (page.isDownloadSuccess()){
onDownloadSuccess(request, page);
} else {
onDownloaderFail(request);
}
}
private void onDownloadSuccess(Request request, Page page) {
if (site.getAcceptStatCode().contains(page.getStatusCode())){
pageProcessor.process(page);
extractAndAddRequests(page, spawnUrl);
if (!page.getResultItems().isSkip() && stat.get() == STAT_RUNNING) {
for (Pipeline pipeline : pipelines) {
pipeline.process(page.getResultItems(), this);
}
}
if (page.getHeaders() != null && page.getHeaders().get(Constant.INCREMENTAL_RUN) != null) {
this.site.getHeaders().put(Constant.INCREMENTAL_RUN, "yes");
if (pageProcessor instanceof BasePageProcessor) {
((BasePageProcessor) pageProcessor).pushMessage2Listener(this.site);
}
}
} else {
logger.info("page status code error, page {} , code: {}", request.getUrl(), page.getStatusCode());
}
sleep(site.getSleepTime());
}
private void onDownloaderFail(Request request) {
if (site.getCycleRetryTimes() == 0) {
sleep(site.getSleepTime());
} else {
// for cycle retry
doCycleRetry(request);
}
}
private void doCycleRetry(Request request) {
Object cycleTriedTimesObject = request.getExtra(Request.CYCLE_TRIED_TIMES);
// 重试的url设置为最高级别, 这样可以保证顺序不中断
if (cycleTriedTimesObject == null) {
addRequest(SerializationUtils.clone(request).setPriority(999).putExtra(Request.CYCLE_TRIED_TIMES, 1));
} else {
int cycleTriedTimes = (Integer) cycleTriedTimesObject;
cycleTriedTimes++;
if (cycleTriedTimes < site.getCycleRetryTimes()) {
addRequest(SerializationUtils.clone(request).setPriority(999).putExtra(Request.CYCLE_TRIED_TIMES, cycleTriedTimes));
}
// 在这里,如果重试次数超过了设定的值,那么也需要记录这条url是下载失败的
else {
throw new RuntimeException("失败重试次数超过阈值, 丢弃该url");
}
}
sleep(site.getRetrySleepTime());
}
protected void sleep(int time) {
try {
Thread.sleep(time);
} catch (InterruptedException e) {
logger.error("Thread interrupted when sleep",e);
}
}
protected void extractAndAddRequests(Page page, boolean spawnUrl) {
if (spawnUrl && CollectionUtils.isNotEmpty(page.getTargetRequests())) {
for (Request request : page.getTargetRequests()) {
addRequest(request);
}
}
}
private void addRequest(Request request) {
if (site.getDomain() == null && request != null && request.getUrl() != null) {
site.setDomain(UrlUtils.getDomain(request.getUrl()));
}
scheduler.push(request, this);
}
protected void checkIfRunning() {
if (stat.get() == STAT_RUNNING) {
throw new IllegalStateException("Spider is already running!");
}
}
public void runAsync() {
Thread thread = new Thread(this);
thread.setDaemon(false);
thread.start();
}
/**
* Add urls to crawl. <br>
*
* @param urls urls
* @return this
*/
public Spider addUrl(String... urls) {
for (String url : urls) {
addRequest(new Request(url));
}
signalNewUrl();
return this;
}
/**
* Download urls synchronizing.
*
* @param urls urls
* @param <T> type of process result
* @return list downloaded
*/
public <T> List<T> getAll(Collection<String> urls) {
destroyWhenExit = false;
spawnUrl = false;
if (startRequests!=null){
startRequests.clear();
}
for (Request request : UrlUtils.convertToRequests(urls)) {
addRequest(request);
}
CollectorPipeline collectorPipeline = getCollectorPipeline();
pipelines.add(collectorPipeline);
run();
spawnUrl = true;
destroyWhenExit = true;
return collectorPipeline.getCollected();
}
protected CollectorPipeline getCollectorPipeline() {
return new ResultItemsCollectorPipeline();
}
public <T> T get(String url) {
List<String> urls = WMCollections.newArrayList(url);
List<T> resultItemses = getAll(urls);
if (resultItemses != null && resultItemses.size() > 0) {
return resultItemses.get(0);
} else {
return null;
}
}
/**
* Add urls with information to crawl.<br>
*
* @param requests requests
* @return this
*/
public Spider addRequest(Request... requests) {
for (Request request : requests) {
addRequest(request);
}
signalNewUrl();
return this;
}
private void waitNewUrl() {
newUrlLock.lock();
try {
//double check
if (threadPool.getThreadAlive() == 0 && exitWhenComplete) {
return;
}
newUrlCondition.await(emptySleepTime, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
logger.warn("waitNewUrl - interrupted, error {}", e);
} finally {
newUrlLock.unlock();
}
}
private void signalNewUrl() {
try {
newUrlLock.lock();
newUrlCondition.signalAll();
} finally {
newUrlLock.unlock();
}
}
public void start() {
runAsync();
}
public void stop() {
if (stat.compareAndSet(STAT_RUNNING, STAT_STOPPED)) {
logger.info("Spider " + getUUID() + " stop success!");
} else {
logger.info("Spider " + getUUID() + " stop fail!");
}
endTime = new Date();
}
/**
* start with more than one threads
*
* @param threadNum threadNum
* @return this
*/
public Spider thread(int threadNum) {
checkIfRunning();
this.threadNum = threadNum;
if (threadNum <= 0) {
throw new IllegalArgumentException("threadNum should be more than one!");
}
return this;
}
/**
* start with more than one threads
*
* @param executorService executorService to run the spider
* @param threadNum threadNum
* @return this
*/
public Spider thread(ExecutorService executorService, int threadNum) {
checkIfRunning();
this.threadNum = threadNum;
if (threadNum <= 0) {
throw new IllegalArgumentException("threadNum should be more than one!");
}
this.executorService = executorService;
return this;
}
public boolean isExitWhenComplete() {
return exitWhenComplete;
}
/**
* Exit when complete. <br>
* True: exit when all url of the site is downloaded. <br>
* False: not exit until call stop() manually.<br>
*
* @param exitWhenComplete exitWhenComplete
* @return this
*/
public Spider setExitWhenComplete(boolean exitWhenComplete) {
this.exitWhenComplete = exitWhenComplete;
return this;
}
public boolean isSpawnUrl() {
return spawnUrl;
}
/**
* Get page count downloaded by spider.
*
* @return total downloaded page count
* @since 0.4.1
*/
public long getPageCount() {
return pageCount.get();
}
/**
* Get running status by spider.
*
* @return running status
* @see Spider.Status
* @since 0.4.1
*/
public Spider.Status getStatus() {
return Spider.Status.fromValue(stat.get());
}
public enum Status {
Init(0), Running(1), Stopped(2);
private Status(int value) {
this.value = value;
}
private int value;
int getValue() {
return value;
}
public static Spider.Status fromValue(int value) {
for (Spider.Status status : Spider.Status.values()) {
if (status.getValue() == value) {
return status;
}
}
//default value
return Init;
}
}
/**
* Get thread count which is running
*
* @return thread count which is running
* @since 0.4.1
*/
public int getThreadAlive() {
if (threadPool == null) {
return 0;
}
return threadPool.getThreadAlive();
}
/**
* Whether add urls extracted to download.<br>
* Add urls to download when it is true, and just download seed urls when it is false. <br>
* DO NOT set it unless you know what it means!
*
* @param spawnUrl spawnUrl
* @return this
* @since 0.4.0
*/
public Spider setSpawnUrl(boolean spawnUrl) {
this.spawnUrl = spawnUrl;
return this;
}
@Override
public String getUUID() {
if (uuid != null) {
return uuid;
}
if (site != null) {
return site.getDomain();
}
uuid = UUID.randomUUID().toString();
return uuid;
}
public Spider setExecutorService(ExecutorService executorService) {
checkIfRunning();
this.executorService = executorService;
return this;
}
@Override
public Site getSite() {
return site;
}
public List<SpiderListener> getSpiderListeners() {
return spiderListeners;
}
public Spider setSpiderListeners(List<SpiderListener> spiderListeners) {
this.spiderListeners = spiderListeners;
return this;
}
public Date getStartTime() {
return startTime;
}
public Scheduler getScheduler() {
return scheduler;
}
/**
* Set wait time when no url is polled.<br><br>
*
* @param emptySleepTime In MILLISECONDS.
*/
public void setEmptySleepTime(int emptySleepTime) {
this.emptySleepTime = emptySleepTime;
}
public String getSpiderType() {
return spiderType;
}
public Spider setSpiderType(String spiderType) {
this.spiderType = spiderType;
return this;
}
public int getThreadNum() {
return threadNum;
}
public Date getUpdateTime() {
return updateTime;
}
public Date getEndTime() {
return endTime;
}
public ConcurrentHashMap<String, Site> getDynamicSite() {
return dynamicSite;
}
public Spider setDynamicSite(ConcurrentHashMap<String, Site> dynamicSite) {
this.dynamicSite = dynamicSite;
return this;
}
public Spider setIncrementalRun(boolean incrementalRun) {
this.incrementalRun = incrementalRun;
return this;
}
public void setTopLimit(boolean topLimit) {
this.topLimit = topLimit;
}
// 判断是否需要增量爬取,并且site的header中是否已经到了增量位置
public boolean checkIncrementalRunAndSite() {
return incrementalRun && topLimit;
}
}

这里可以看到onDownloadSuccess这个方法,主要就是修改了这里,判断一下page里面的headers,是否含有到达阈值的key,如果有的话那么就发消息通知一下listener,下面是BasePageProcessor
import com.ahdx.common.Constant;
import com.ahdx.monitor.MySpiderMonitor;
import com.ahdx.monitor.MySpiderStatus;
import com.ahdx.spider.Spider;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.Map;
public abstract class BasePageProcessor implements PageProcessor {
public void pushMessage2Listener(Site site) {
MySpiderMonitor monitor = MySpiderMonitor.instance();
if (site != null && site.getHeaders() != null && "yes".equalsIgnoreCase(site.getHeaders().get(Constant.INCREMENTAL_RUN))) {
String key = site.getHeaders().get(Constant.SPIDER_UUID);
// 从监控对象中取对应的spider进行停止
Map<String, MySpiderStatus> spiderStatuses = monitor.getSpiderStatuses();
MySpiderStatus spiderStatus = spiderStatuses.get(key);
if (spiderStatus != null) {
Spider spider = spiderStatus.getSpider();
if (spider != null) {
spider.setTopLimit(true);
}
}
}
}
}
说一下这里的key的获取,是我在创建spider的时候将uuid设置到site中去的,目的就是为了方便通过uuid在监控模块中快速找到需要操作的spider,这个方法中可以直接调用spider.stop();或者可以做一些其他更复杂的操作,我是将spider中判断到达阈值的topLimit设置为true,这样的话,在Scheduler的poll方法中可以判断spider是否不需要再继续执行了,而是可以清空任务并停止。
import com.ahdx.spider.Spider;
import org.apache.commons.lang3.StringUtils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.scheduler.RedisPriorityScheduler;
import java.util.Set;
public class MyRedisPriorityScheduler extends RedisPriorityScheduler {
private static final String ZSET_PREFIX = "zset_";
private static final String QUEUE_PREFIX = "queue_";
private static final String NO_PRIORITY_SUFFIX = "_zore";
private static final String PLUS_PRIORITY_SUFFIX = "_plus";
private static final String MINUS_PRIORITY_SUFFIX = "_minus";
private static final String ZSET_SUFFIX = "_error";
public MyRedisPriorityScheduler(String host) {
super(host);
}
public MyRedisPriorityScheduler(JedisPool pool) {
super(pool);
}
private String getZsetPlusPriorityKey(Task task) {
return ZSET_PREFIX + task.getUUID() + PLUS_PRIORITY_SUFFIX;
}
private String getQueueNoPriorityKey(Task task) {
return QUEUE_PREFIX + task.getUUID() + NO_PRIORITY_SUFFIX;
}
private String getZsetMinusPriorityKey(Task task) {
return ZSET_PREFIX + task.getUUID() + MINUS_PRIORITY_SUFFIX;
}
private String getZsetErrorNoPriorityKey(Task task) {
return ZSET_PREFIX + task.getUUID() + ZSET_SUFFIX;
}
/**
* 使用redis作为任务队列的载体挺好的,但是有一个问题是如果任务爬取失败了,那么没有办法从已爬取任务队列中删除,这样重试的时候会导致任务无法进行
* 所以先自定义一个删除的方法
*/
public boolean deleteErrorUrl(Request request, Task task) {
// 获取到去重的队列名称
try (Jedis jedis = super.pool.getResource()) {
return jedis.srem(super.getSetKey(task), request.getUrl()) == 0;
}
}
public boolean pushErrorUrl(Request request, Task task) {
try (Jedis jedis = super.pool.getResource()) {
return jedis.sadd(getZsetErrorNoPriorityKey(task), request.getUrl()) == 0;
}
}
/**
* @update 2021年5月17日10:37:49
* @desc 实现增量爬取,重写获取request的业务逻辑
* @param task spider
* @return 爬取任务
*/
@Override
public synchronized Request poll(Task task) {
try (Jedis jedis = pool.getResource()) {
if (task instanceof Spider) {
Spider spider = (Spider) task;
if (spider.checkIncrementalRunAndSite()) {
spider.stop();
// 光停止本地的爬虫还不行,还需要清空各个任务列表中的任务
this.clearTask(jedis, task);
}
}
String url = getRequest(jedis, task);
if (StringUtils.isBlank(url)) {
return null;
}
// 目前对于重试的url设置了最高权限,失败后立即重试,所以不需要再去重试任务列表中取任务了
// return getExtrasInItem(jedis, url, task);
return new Request(url);
}
}
private String getRequest(Jedis jedis, Task task) {
String url;
Set<String> urls = jedis.zrevrange(getZsetPlusPriorityKey(task), 0, 0);
if (urls.isEmpty()) {
url = jedis.lpop(getQueueNoPriorityKey(task));
if (StringUtils.isBlank(url)) {
urls = jedis.zrevrange(getZsetMinusPriorityKey(task), 0, 0);
if (!urls.isEmpty()) {
url = urls.toArray(new String[0])[0];
jedis.zrem(getZsetMinusPriorityKey(task), url);
}
}
} else {
url = urls.toArray(new String[0])[0];
jedis.zrem(getZsetPlusPriorityKey(task), url);
}
return url;
}
private synchronized void clearTask(Jedis jedis, Task task) {
jedis.del(getZsetPlusPriorityKey(task));
jedis.del(getZsetMinusPriorityKey(task));
jedis.del(getQueueNoPriorityKey(task));
}
/**
* 获取剩余任务数量
* @param task
* @return
*/
@Override
public int getLeftRequestsCount(Task task) {
try (Jedis jedis = super.pool.getResource()) {
Long queueSize = jedis.llen(getQueueNoPriorityKey(task));
Long plusSize = jedis.zcard(getZsetPlusPriorityKey(task));
Long minSize = jedis.zcard(getZsetMinusPriorityKey(task));
return (int) (queueSize + plusSize + minSize);
}
}
@Override
public int getTotalRequestsCount(Task task) {
try (Jedis jedis = super.pool.getResource()) {
Long size = jedis.scard(getSetKey(task));
Long errorSize = jedis.scard(getZsetErrorNoPriorityKey(task));
return (int) (size + errorSize);
}
}
}

这个方法中可以看到,如果spider增量爬取标识是true,那么就可以进行停止并清空redis爬取队列的操作了。最后注释掉的那一行是原生的方法,他是先从待爬取的队列中先取,如果没有了继续从重试队列中取,但是我自己对重试的url设置了比较大的权限,会在失败时候立刻重试,所以不需要再从重试队列中取任务了,这里可以根据自己的业务需求来改。
?好了,至此增量爬取的逻辑也就结束了。
总结
这篇文章的代码大部分都不能copy过去直接使用的,所以其实是讲了一下我大概的思路。哈哈,希望能对大家有一些帮助吧!干饭去了~
原文链接:https://blog.csdn.net/krito1994/article/details/116975742























